Article
Deploy AWS Glue ETL Using AWS CodePipelines
Deploy AWS Glue ETL Using AWS CodePipelines
In this post, we discuss a centralized deployment solution utilizing AWS CodePipelines for data lakes. The solution implements continuous integration of data lake infrastructure, data processing and ETL jobs through mult-accounts.
Technology Stack
AWS Glue
AWS Lambda
AWS SystemManager
AWS CDK
AWS CodeCommit
AWS
CodeBuild
AWS CodePipelines
AWS IAM
AWS SNS
AWS StepFunctions
AWS
CloudFormation
AWS EventBridge
AWS SecretManager
continuous Deployment Solution
The following deployment strategy is based on the following best practice design
principles:
1. Dedicated AWS account to run CDK pipelines.
2. One or more AWS accounts into which the data lake is deployed.
3. The data lake infrastructure has a dedicated source code repository.
Data lake infrastructure is rarely re-deployed and it makes good sense to
have
it's own repository to add a level of isolation from frequently changing ETL
jobs.
4. Each ETL job or a group of similar ETL jobs has a dedicated source code
repository. Each/group of ETL jobs may
have unique AWS service, orchestration, and configuration requirements.
Therefore, a dedicated source code repository allow more flexibly in
building and maintaining the
jobs.
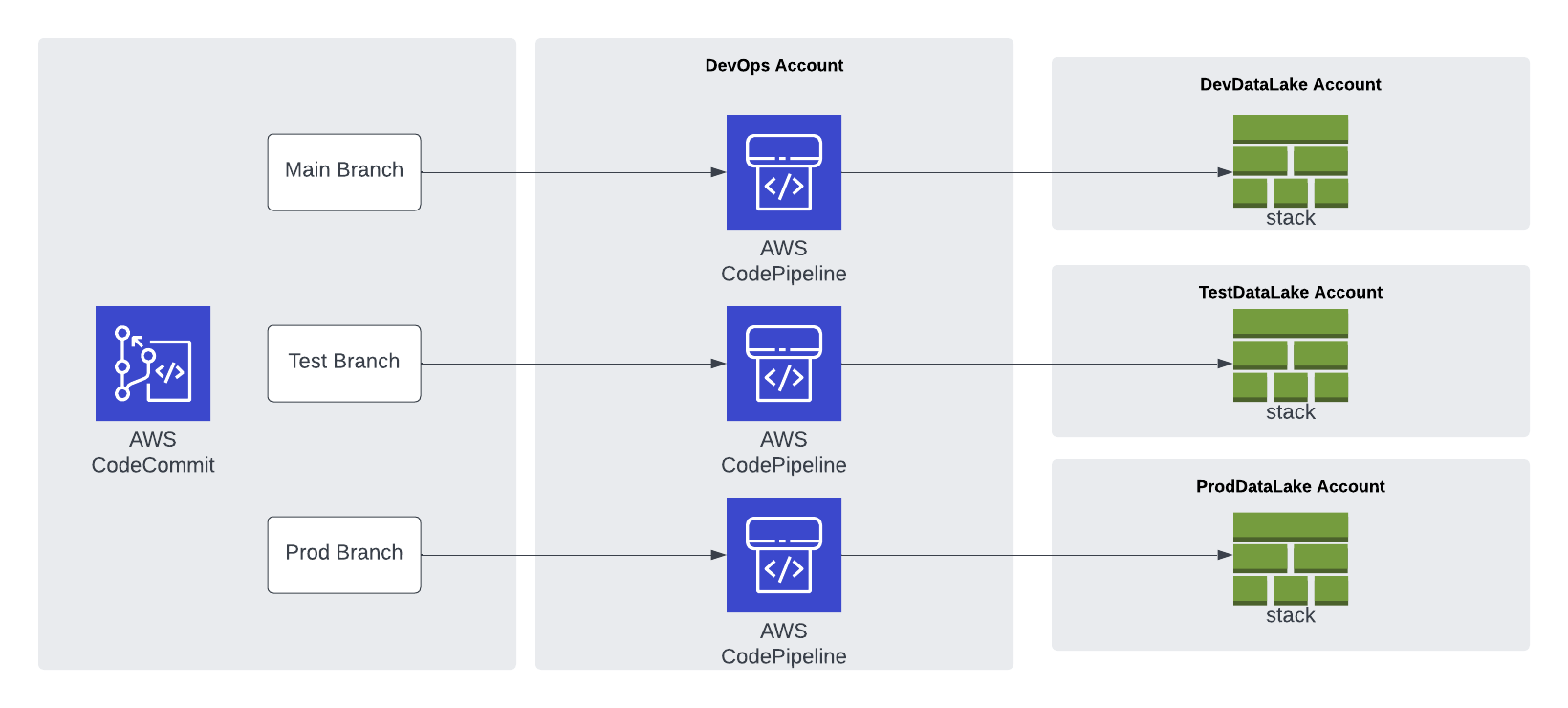
The AWS CodeCommit repository is organized into three branches: dev (main),
test, and prod. A centralized deployment account contains three separate CDK
Pipelines and
each pipeline is sourced from a dedicated branch. Here we choose a branch-based
software development method in order to demonstrate the strategy in more complex
scenarios where integration testing and validation layers require human
intervention. This
facilitates the propagation of changes through
environments without blocking independent development priorities. We accomplish
this by
isolating resources across environments in the central deployment account,
allowing
for the independent management of each environment, and avoiding
cross-contamination
during each pipeline’s self-mutating updates.
A closer look at the CICD pipeline and deployment flow
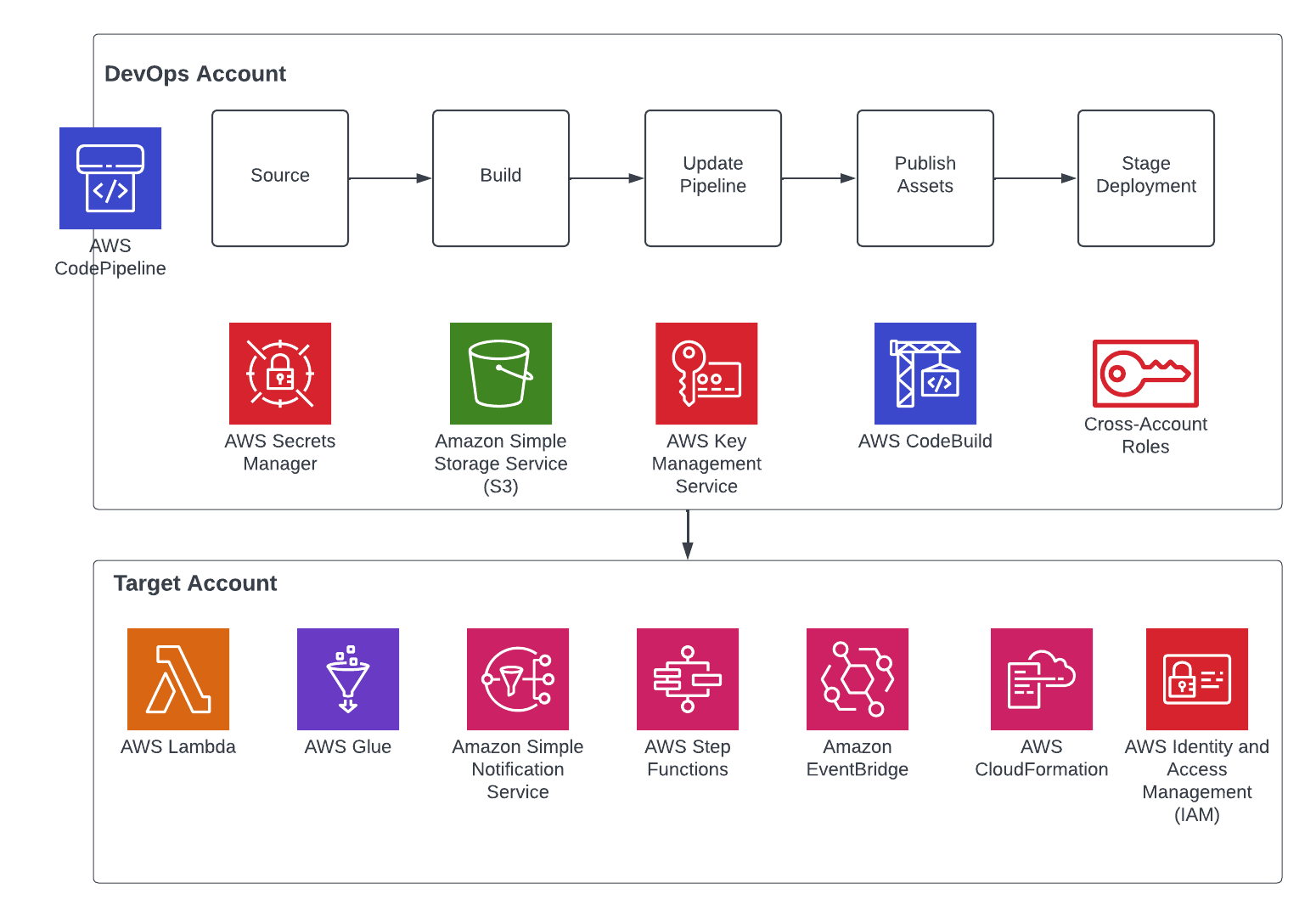
Each repository represents a cloud infrastructure code definition. This includes the pipelines construct definition. Pipelines have one or more actions, such as cloning the source code (source action) and synthesizing the stack into an AWS CloudFormation template (synth action). Each pipeline has one or more stages, such as testing and deploying.
CICD Pipeline Explained
1. The DevOps administrator checks in the code to the repository.
2. The DevOps administrator (with elevated access) facilitates a one-time manual
deployment on a target environment. Elevated access includes administrative
privileges on the central deployment account and target AWS environments.
3. CodePipeline periodically listens to commit events on the source code
repositories. This is the self-mutating nature of CodePipeline. It’s configured
to work with and can update itself according to the provided definition.
4. Code changes made to the main repo branch are automatically deployed to the
data lake dev environment.
5. Code changes to the repo test branch are automatically deployed to the test
environment.
6. Code changes to the repo prod branch are automatically deployed to the prod
environment.
Advantages
Configuration-driven deployment
Source code and AWS Secrets Manager allow deployments to utilize values that are declared globally in a single location. Providig consistent management of global configurations and dependencies such as resource names, AWS account Ids, Regions, and VPC CIDR ranges. Similarly, the CDK Pipelines export outputs from CloudFormation stacks for later consumption via other resources.
Repeatable and consistent deployment of new ETL jobs
Continuous integration and continuous delivery pipelines allow teams to deploy to production more frequently. Code changes can be safely and securely propagated through environments and released for deployment. This allows rapid iteration on data processing jobs, and these jobs can be changed in isolation from pipeline changes, resulting in reliable workflows.
Scalable and centralized deployment model
We utilize a scalable and centralized deployment model to deliver end-to-end automation. This allows DevOps and data engineers to use the single responsibility principal while maintaining precise control over the deployment strategy and code quality. The model can readily be expanded to more accounts, and the pipelines are responsive to custom controls within each environment, such as a production approval layer.